
循环依赖产生原因
在创建B类的Bean的过程中,如果B类中存在一个A类的a属性,那么在创建B的Bean的过程中就需要A类对应的Bean,但是,触发B类Bean的创建的条件是A类Bean在创建过程中的依赖注入,所以这里就出现了循环依赖:
ABean创建-->依赖了B属性-->触发BBean创建--->B依赖了A属性--->需要ABean(但ABean还在创建过程中)
从而导致ABean创建不出来,BBean也创建不出来。
三级缓存:
singletonObjects:缓存经过了完整生命周期的单例bean
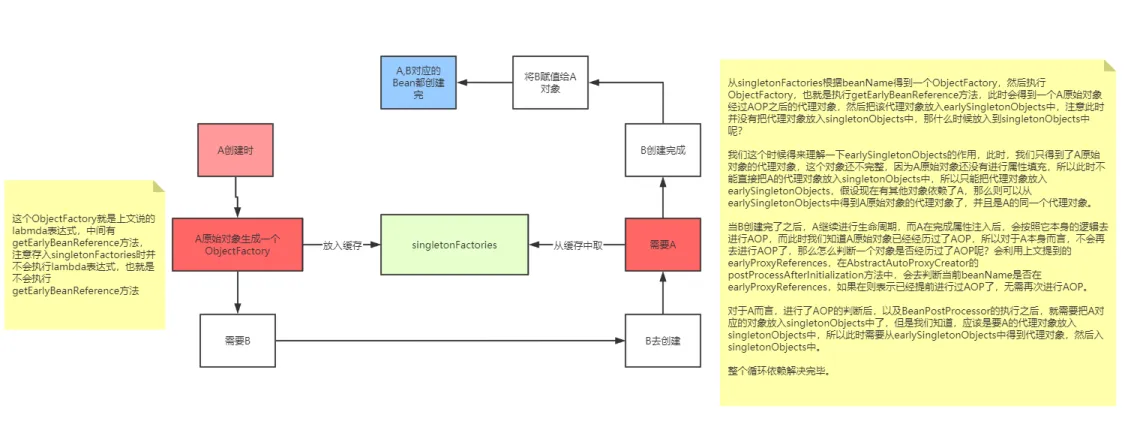
earlySingletonObjects:缓存未经过完整生命周期的bean,如果某个bean出现了循环依赖,就会提前把这个暂时未经过完整生命周期的bean放入earlySingletonObjects中,这个bean如果要经过AOP,那么就会把代理对象放入earlySingletonObjects中,否则就是把原始对象放入earlySingletonObjects,但是不管怎么样,就是代理对象,代理对象所代理的原始对象也是没有经过完整生命周期的,所以放入earlySingletonObjects我们就可以统一认为是未经过完整生命周期的bean。
singletonFactories:缓存的是一个ObjectFactory,也就是一个Lambda表达式。在每个Bean的生成过程中,经过实例化得到一个原始对象后,都会提前基于原始对象暴露一个Lambda表达式,并保存到三级缓存中,这个Lambda表达式可能用到,也可能用不到,如果当前Bean没有出现循环依赖,那么这个Lambda表达式没用,当前bean按照自己的生命周期正常执行,执行完后直接把当前bean放入singletonObjects中,如果当前bean在依赖注入时发现出现了循环依赖(当前正在创建的bean被其他bean依赖了),则从三级缓存中拿到Lambda表达式,并执行Lambda表达式得到一个对象,并把得到的对象放入二级缓存((如果当前Bean需要AOP,那么执行lambda表达式,得到就是对应的代理对象,如果无需AOP,则直接得到一个原始对象))。
其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
为什么需要第三级缓存
我们可以发现,现在Spring所用的singletonFactories,为了调和不同的情况,在singletonFactories中存的是lambda表达式,这样的话,只有在出现了循环依赖的情况,才会执行lambda表达式,才会进行AOP,也就说只有在出现了循环依赖的情况下才会打破Bean生命周期的设计,如果一个Bean没有出现循环依赖,那么它还是遵守了Bean的生命周期的设计的。

发表评论