
回收流程:
初始标记(STW,标记GC Root直接关联对象)->并发标记(标记GC Root 所有关联对象)->重新标记(STW)->并发清除(清除不可达对象回收空间,浮动垃圾)
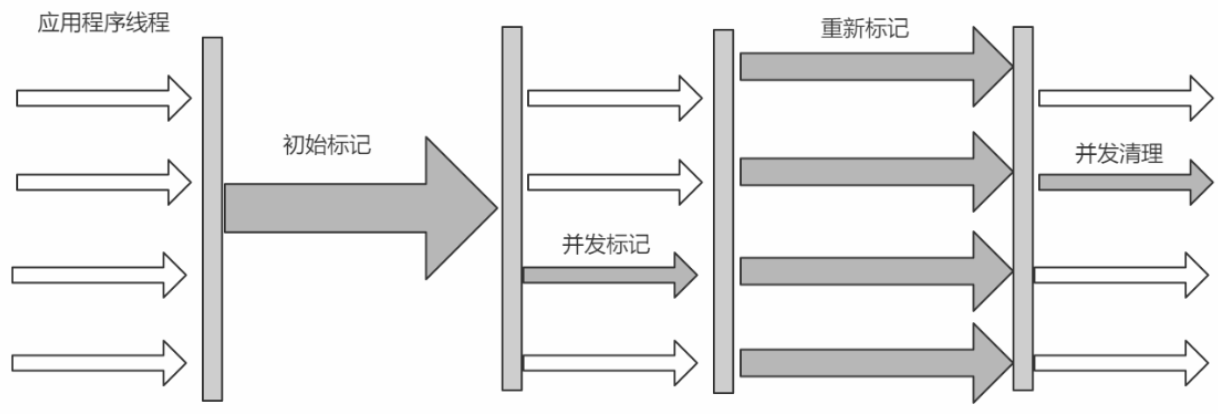
后面还一步,是并发重置。
CMS的两种模式和一种策略:
Backgroud CMS:
在并发标记之后,重新标记之前多了两步:
并发预处理和可中止的预处理:Eden空间使用超过2M的时候启动可中断的并发预清理(CMS-concurrent-abortable-preclean),到Eden空间使用率到达50%的时候中断(但不是结束),进入Remark(重新标记阶段)
Foregroud CMS:
并发失败才会走的模式,关于并发失败官方的描述:
如果并发搜集器不能在年老代填满之前完成不可达(unreachable)对象的回收,或者年老代中有效的空闲内存空间不能满足某一个内存的分配请求,此时应用会被暂停,并在此暂停期间开始垃圾回收,直到回收完成才会恢复应用程序。这种无法并发完成搜集的情况就成为 并发模式失败(concurrent mode failure),而且这种情况的发生也意味着我们需要调节并发搜集器的参数了。
简单来说,就是我们进行并发标记的时候,内存不够了,这个时候我们会进入STW,并且开始全局Full GC。此时会切换到Serial Old垃圾回收器。
按照默认值,老年代达到92%(公式计算)时,才会触发CMS回收。
CMS的标记压缩算法--MSC
碎片问题也是CMS采用的标记清理算法最让人诟病的地方:Backgroud CMS采用的标记清理算法会导致内存碎片问题,从而埋下发生FullGC导致长时间STW的隐患。
所以如果触发了FullGC,无论是否会采用MSC算法压缩堆,那都是ParNew+CMS组合非常糟糕的情况。因为这个时候并发模式已经搞不定了,而且整个过程单线程,完全STW,可能会压缩堆(是否压缩堆通过上面两个参数控制),真的不能再糟糕了!想象如果这时候业务量比较大,由于FullGC导致服务完全暂停几秒钟,甚至上10秒,对用户体验影响得多大。

发表评论